Monorepo 基本概念
什么是 Monorepo
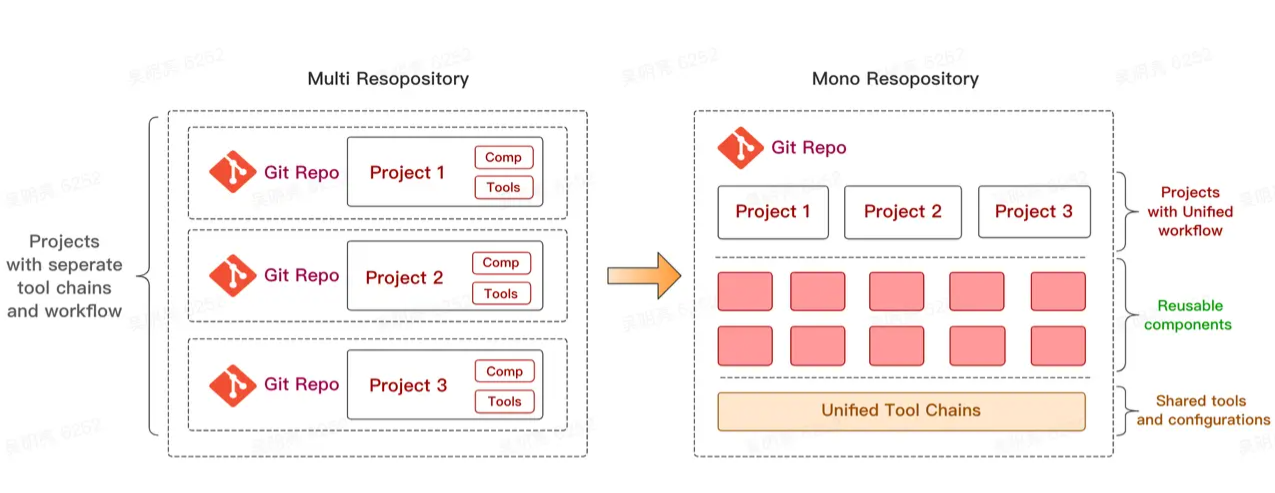
MonoRepo 中文叫单体仓库,对应的还有多体仓库叫MultiRepo。
多体仓库:多个项目保存在互相完全独立的代码仓库内,每个仓库都会有自己的.git文件夹
单体仓库:就是单个项目仓库 (repository),其中包含多个开发项目。虽然这些 project 也许是相关联的,但它们通常在逻辑上相互独立,并被不同的团队负责编写,运行。
MonoRepo 概念上很好理解,就是把多个项目放在一个仓库里面,相对立的是传统的 MultiRepo 模式,即每个项目对应一个单独的仓库来分散管理。
Monorepo 有以下一些优势:
- 代码共享和重用:将相关的项目、组件或库放在同一个仓库中,有助于实现代码的共享和重用。这可以减少重复代码的编写,提高开发效率。
- 协同开发:Monorepo 可以让开发团队更方便地进行协同开发。当多个项目需要同时进行修改时,开发人员可以在同一个仓库中进行修改,减少了在多个仓库之间进行协同的复杂性。
- 版本控制和依赖管理:在 Monorepo 中,所有项目、组件和库共享同一个版本控制系统。这有助于简化依赖管理,确保各个组件之间的兼容性。
Monorepo 是如何诞生的
Monorepo 的诞生并没有一个明确的起点,它是随着软件工程和版本控制系统的发展逐渐形成的一种代码管理策略。
在早期的软件开发过程中,随着项目的增长,开发者们逐渐意识到将不同的项目、组件或库分别存放在独立的代码仓库(称为多仓库策略)会带来一定的问题,例如依赖管理、协同开发等方面的挑战。这促使了人们开始思考如何更好地组织和管理代码。
比如,在维护多个项目的时候,有一些逻辑很有可能会被多次用到,比如一些基础的组件、工具函数,或者一些配置。
通常的做法,就是拷贝一份过来直接使用,但有个问题是,如果这些代码出现 bug、或者需要做一些调整的时候,就得修改多份,维护成本越来越高。
那如何来解决这个问题呢?比较好的方式是将公共组件,或者通用方法抽取出来,作为一个 私有 npm 仓库发布,一旦需要改动,只需要改动一份代码,然后 publish 就行了,对应使用的项目只需要重新 npm install 即可。
但这真的完美了么?我举个例子,比如你引入了 1.1.0 版本的 A 包,某个工具函数出现问题了,你需要做这些事情:
- 去修改一个工具函数的代码
- 发布
1.1.1版本的新包 - 项目中安装新版本的 A。
可能只是改了一行代码,需要走这么多流程。然而开发阶段是很难保证不出 bug 的,如果有个按钮需要改个样式,又需要把上面的流程重新走一遍……停下来想想,这些重复的步骤真的是必须的吗?我们只是想复用一下代码,为什么每次修改代码都这么复杂?
上述的问题其实是 MultiRepo普遍存在的问题,因为不同的仓库工作区的割裂,导致复用代码的成本很高,开发调试的流程繁琐,甚至在基础库频繁改动的情况下让人感到很抓狂,体验很差。
这是 MultiRepo 最主要的缺点,当然还有在 MultiRepo 当中,每个项目需要单独配置开发环境、配置 CI 流程、配置部署发布流程等等,这些都是重复的事情,而且维护起来就比较麻烦。
而 Monorepo 作为一种新的代码管理策略,逐渐受到了一些大型公司(如 Google、Facebook 和 Twitter)的青睐。这些公司拥有庞大的代码库和开发团队,他们发现将相关的项目、组件或库放在一个代码仓库中,有助于实现代码共享、协同开发和版本控制。随着这些公司的成功实践,Monorepo 逐渐在软件开发领域获得了更广泛的关注和应用。
以上就是 Monorepo 诞生的原因。
Monorepo 的适用场景
下面我将以前端开发为例,说明 Monorepo 的适用场景:
- 组件库开发:假设你的团队正在开发一个前端组件库,这个库包含多个功能相近的包,或者这些包之间存在依赖关系。如果将这些包拆分在不同仓库里,那么面临要跨多个包进行更改时,工作会非常繁琐和复杂。为了简化流程,很多大型项目采用了 Monorepo 的做法,即把所有的包放在一个仓库中管理。Babel、React、Vue、Jest 等都使用了 Monorepo 的管理方式。
- 大型前端应用:对于一个包含多个子模块或微服务的大型前端应用,使用 Monorepo 可以帮助你更好地组织和管理代码。例如,你可以将应用的各个子模块(如用户管理、订单管理等)放在同一个代码仓库中,这样当你需要修改多个模块的共享代码时,可以更方便地进行协同开发。
- 前后端分离的项目:在前后端分离的项目中,前端和后端代码可能需要共享一些配置、数据模型或工具函数。使用 Monorepo 可以让你将前端和后端代码放在同一个仓库中,从而实现更容易的代码共享和协同开发。
- 跨平台项目:如果你的前端项目需要支持多个平台(如 Web、移动端、桌面端等),你可以使用 Monorepo 来管理这些平台的相关代码。这样可以确保各个平台的代码共享相同的核心库和依赖,同时也便于进行跨平台的协同开发。
- 分角色的相同系统:一个基本相同的前端项目,但是分成了客户端和运维端。这种可以使用 Monorepo 。
Monorepo 的缺点和局限性
尽管 Monorepo 在某些场景下具有一定的优势,但它也有一些潜在的缺点和局限性。以下是针对前端开发的一些例子:
- 仓库过大:使用 Monorepo 管理多个项目、组件或库可能导致代码仓库变得非常庞大。过大的仓库可能会导致克隆、拉取更新等操作变得缓慢,从而影响开发者的工作效率。此外,对于新加入项目的开发者来说,过大的代码仓库也可能增加他们的学习和理解成本。
- 权限管理和代码审查:将所有项目、组件和库放在同一个仓库中可能会导致权限管理和代码审查变得更加复杂。例如,你可能需要为不同的项目设置不同的访问权限和代码审查规则。在 Monorepo 中实现这些功能可能需要更多的工具和设置。
- 持续集成/持续部署 (CI/CD) 配置复杂:在 Monorepo 中,由于多个项目共享同一个仓库,你可能需要为每个项目单独配置 CI/CD 流程。这可能会导致 CI/CD 配置变得复杂,同时也可能增加构建和部署的时间。
- 依赖管理:虽然 Monorepo 可以简化依赖管理,但在某些情况下,它也可能带来新的问题。例如,当多个项目共享同一个依赖库时,升级该库可能会影响到所有项目。在 Monorepo 中,你需要确保所有项目都可以正常工作,这可能会增加升级依赖库的难度和风险。
- 限制了独立发布:使用 Monorepo 管理多个项目时,可能会限制项目的独立发布。当一个项目需要发布新版本时,你可能需要确保所有依赖该项目的其他项目也已经准备好发布。这可能会导致项目之间的耦合,影响发布的灵活性。
基于此,在下面情况下不推荐使用 Monorepo :
- 项目规模较小:如果你的前端项目规模较小,只涉及到一个或少数几个应用,并且没有大量通用组件和工具需要共享,那么使用 Monorepo 可能会增加不必要的复杂性。在这种情况下,采用多个独立的仓库(MultiRepo)可能更加简单和高效。
- 团队协作较少:如果你的前端项目由一个较小的团队开发,且团队成员之间的协作较少,那么使用 Monorepo 可能无法充分发挥其协同开发的优势。在这种情况下,采用 MultiRepo 可能更适合团队的工作流程。
- 独立部署和运维需求:如果你的前端项目包含多个相互独立的应用,它们需要独立进行部署和运维,那么使用 Monorepo 可能会增加部署和运维的复杂性。在这种情况下,采用 MultiRepo 可以让你更方便地管理各个应用的部署和运维。
- 不同技术栈和依赖管理:如果你的前端项目涉及到多个应用,它们使用了不同的技术栈或依赖库,那么使用 Monorepo 可能会导致依赖管理变得复杂。在这种情况下,采用 MultiRepo 可以让你更方便地为每个应用管理其特定的技术栈和依赖。
- 权限和安全性:如果你的前端项目需要严格的权限控制和安全性要求,那么使用 Monorepo 可能会带来一定的风险。因为在 Monorepo 中,所有代码都存储在同一个仓库中,这可能导致权限控制和敏感信息泄露的风险增加。在这种情况下,采用 MultiRepo 可以让你更方便地为每个仓库设置独立的权限和安全策略。
Monorepo 实践
好了,我现在明白了 Monorepo 的优缺点和适用范围,那么该如何搭建一个基于 Monorepo 的项目工程呢?
方案选择
Monorepo 的工具主要解决以下问题:
- 项目之间的互相依赖问题(后来的 workspace 解决了这个问题)
- 支持拓扑排序执行构建指令,无需到每个包单独构建
- 版本管理和发布,无需到每个包单独修改
在选择 Monorepo 管理方案时,有以下两种主流方案
- Lerna + Yarn
- pnpm + s
两者都可以,不过 pnpm 对性能、存储空间优化更好,也是目前的主流方案。
下面就使用 pnpm 的 workspace 来创建 monorepo 代码仓库。
基于 pnpm 的 Monorepo 实践
项目搭建
1、全局安装 pnpm
npm install -g pnpm
// 验证:pnpm -v
2、创建一个名为 my-monorepo 的文件夹
3、初始化 pnpm 工作区
pnpm init
这将生成一个 package.json 文件。
4、编辑 package.json,添加 workspaces 字段
"workspaces": [
"packages/*"
],
5、创建 packages 文件夹。pnpm 将 packages 下的子目录都视为一个项目。
6、创建 pnpm-workspace.yaml 文件
packages:
-"packages/*";
这段代码表示:pnpm 会将 packages/ 目录下的所有子目录(如 packages/a、packages/b)视为独立的包,并纳入工作区管理。
7、安装依赖。在 Monorepo 根目录,执行 pnpm install,会自动安装所有依赖并且而包与包之间的依赖,workspace 会处理
项目运行
如果我们想启动子项目 vite-project 的 dev 模式,可以执行下面指令:
pnpm --filter vite-project run dev
--filter简写为-F
或者直接在 Monorepo 的 scripts 中添加下面指令即可:
"scripts": {
"dev:vite1": "pnpm --filter vite-project run dev"
},
过滤--filter允许您将命令限制于特定的子项目。
如果想要在每个子项目中都执行命令可以使用 -r 选项
根据是否包含根项目,又分成两组:
包含根项目:
installpublishupdate
不包括根项目 :
execruntestadd
pnpm -r run build
共享公共函数
在 packages 文件夹下新增 utils 文件夹,并且新增一个 index.js 文件:
export function myUtilFunction() {
console.log("myUtilFunction");
}
然后,因为 packages 下面的每个文件夹都是一个子项目,所以也必须有 package.json 文件:
{
"name": "dt-utils",
"version": "1.0.0",
"main": "index.js",
"keywords": [],
"author": "Daotin",
"license": "ISC"
}
然后,如果需要在其他子项目中使用,需要在子项目的 package.json 中引入该依赖:
// 步骤1、使用指令添加:pnpm -F vite-project add dt-utils,或者使用下面方式:
"dependencies": {
"dt-utils": "workspace:*"
},
// 步骤2、再次执行 `pnpm install`,这个命令会创建需要的软链接,使得你的子项目可以正确地引用 `dt-utils` 包。
pnpm 支持 workspace 协议,需要把依赖改为这样的形式,这样查找依赖就是从 workspace 里查找,而不是从 npm 仓库了。
需要注意的是,
workspace:*只能在 monorepo 中使用,如果你打算将你的子项目发布到外部,你需要先将workspace:*替换为实际的版本号。
于是在子项目中就可以这样使用了:
import { myUtilFunction } from "dt-utils";
myUtilFunction();
然后共享组件库,共享 assets 资源的思路都是一样的:
- 需要
package.json。 - 需要入口
index.js,并且导出你的组件或者资源。 - 在使用该共享组件库,共享 assets 的子项目中使用
pnpm -F vite-project add dt-assets进行安装依赖 pnpm install创建软链接
版本管理和发布
Changesets 插件
Changesets 是一个版本管理工具,主要用于管理项目中各个包的版本号和发布记录。它的主要优点在于:能够根据每个提交的变动,自动更新包的版本号,生成变更日志,并发布新版本。
它主要解决的问题是:
- 多包管理:一个 Monorepo 里可能有几十上百个 package。
- 版本控制:哪些包需要发新版本?发的是 patch、minor 还是 major?
- 自动生成 changelog:根据改动记录,自动生成更新日志。
- 自动发包:配合 CI/CD,可以一键自动发 N 个 npm 包。
简单说,changeset = “记录改动 → 生成版本 → 更新日志 → 自动发布” 的流水线工具。
Changesets 的工作流大致如下:
- 当你对代码进行了更改后,运行
yarn changeset或npx changeset命令。这个命令会引导你选择哪些包应该被版本更新,以及这次更新的类型(主要更新、次要更新或补丁更新)。 - 这个命令会生成一个 changeset 文件,记录了哪些包应该被更新,以及更新的类型。这个文件应该被提交到版本控制系统中。
- 当你准备发布新版本时,运行
yarn changeset version或npx changeset version命令。这个命令会根据所有未处理的 changeset 文件,更新相关包的版本号,并生成变更日志。 - 最后,运行
yarn changeset publish或npx changeset publish命令发布新版本。
Changesets 和 pnpm
Changesets 和 pnpm 可以很好地配合使用,以支持 monorepo 的版本管理和发布。你只需要在你的项目中安装 Changesets,并遵循上述的工作流。
具体来说,你可以按照以下步骤来配置 Changesets 和 pnpm:
1、要在 pnpm 工作空间上配置 changesets,请将 changesets 作为开发依赖项安装在工作空间的根目录中:
pnpm add -Dw @changesets/cli
2、然后 changesets 的初始化命令:
pnpm changeset init
这时候,你会发现,项目根目录下多了一个 .changeset 目录,其中 config.json 是 changesets 的配置文件。请注意,我们需要把这个目录一起提交到 git 上。
注意:如果你的默认分支不叫 main,你可以在 .changeset/config.json 文件中修改 baseBranch 字段,使其指向你的默认分支。例如,如果你的默认分支叫 master,你可以将 baseBranch 设置为 master
生成 changeset 文件
什么叫 changeset 呢?
就是一次改动的集合,可能一次改动会涉及到多个 package,多个包的版本更新,这合起来叫做一个 changeset。
要生成新的 changesets,请在仓库的根目录中执行 pnpm changeset。
pnpm changeset
这时候我们需要选择要发布的包以及包的版本类型(patch、minor、minor),changeset 会通过 git diff 和构建依赖图来获得要发布的包。
这时候,会发现多出来一个文件名随机的 changeset 文件:
这个文件的本质是对包的版本和 Changelog 做一个预存储,我们也可以在这些文件中修改信息。随着不同开发者进行开发迭代积累,changeset 可能会有多个的。
这些 changeset 文件是需要一并提交到远程仓库中的。在后面的包发布后,这些 changeset 文件是会被自动删除掉的。
更新版本
你可以执行 version 命令来生成最终的 CHANGELOG.md 还有更新版本信息:
pnpm changeset version
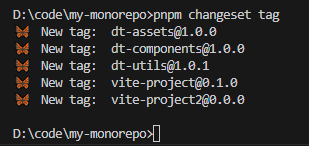
还可以通过pnpm changeset tag自动打 tag:
发布到 npm 仓库
更新完版本自然是要 publish 到 npm 仓库的。然后我们执行以下命令进行发布,并且还会自动打 tag:
pnpm changeset publish
这就是 changeset 的作用。
没有 Changeset 之前,大家是怎么做的?
手工维护:
- 在每个 package 的 package.json 里手动改 version。
- 自己写 CHANGELOG.md。
- 发布的时候手动执行 npm publish
- 缺点:容易出错(忘记 bump 版本、忘记同步依赖版本、日志不一致)。
以上教程的配置代码仓库地址:https://github.com/Daotin/monorepo-demo
Turborepo
Turborepo 是一个高性能构建系统,由 Rust 编写,主要用于 JavaScript 和 TypeScript 的单仓库(monorepo)项目。
Turborepo 通过智能缓存和并行任务执行,减少重复计算,只重新构建发生变化的部分,从而显著缩短构建时间。
解决什么问题?
- 构建速度慢:传统的 Monorepo 在执行构建(Build)、测试(Test)、和部署(Deploy)时,可能会因为重复计算和不必要的任务执行导致速度变慢。
- 任务管理复杂:随着 Monorepo 规模增大,管理各个子项目的依赖、任务运行顺序和缓存变得复杂。
- 缺乏智能缓存:大部分 Monorepo 工具(如 Lerna)对构建任务没有高效的缓存机制,导致重复执行已计算过的任务,浪费时间。
- 分布式 CI/CD 效率低:在 CI/CD 中,所有任务通常都从头执行,而没有智能地复用已有构建结果。
这些延迟会严重影响您的团队构建软件的方式,尤其是在大规模情况下。反馈循环需要快速,以便开发人员能够快速交付高质量的代码。
Turborepo 解决了单库的扩展问题。通过缓存存储了所有任务的结果,这意味着你的持续集成(CI)从不需要重复做相同的工作。
核心特点:
- 智能缓存(Incremental Caching)
- Turborepo 使用 基于哈希的构建缓存,确保相同的任务不会被重复执行。
- 只要输入不变(代码、依赖、环境变量等),Turborepo 就可以直接跳过任务,复用之前的结果。
- 这极大地提高了构建和测试速度,减少 CI/CD 运行时间。
- 任务管道(Task Pipelines)
- 允许用户定义任务的执行顺序和依赖关系,比如
build任务依赖lint和test任务完成后才能执行。 - Turborepo 通过并行执行任务和依赖管理,提高任务调度效率。
- 允许用户定义任务的执行顺序和依赖关系,比如
- 远程缓存(Remote Caching)
- 可以将本地缓存同步到远程存储,如 Vercel Remote Cache 或者自定义的 S3 存储。
- 团队成员可以共享缓存,在 CI/CD 过程中直接复用计算结果,避免重复执行任务。
- 与现有工具兼容
- 可以与 pnpm、Yarn、npm 配合使用,适配现有的包管理工具。
- 兼容 Next.js、React、TypeScript 等主流技术栈,无需大量改动代码。
- 优化 CI/CD 运行效率
- 由于任务缓存机制,CI/CD 任务不需要每次都重新构建所有包,仅执行变化的部分,大幅缩短 CI/CD 运行时间。
Turborepo 通过 智能缓存 和 任务调度优化 解决了 Monorepo 在大规模项目中的构建性能和任务管理问题,使开发和 CI/CD 变得更加高效。对于需要管理多个子项目但又希望构建速度快、管理简单的团队,Turborepo 是一个强大的工具。
如何把Turborepo接入到当前项目
1、全局和局部安装turbo
确保在开始安装之前已经创建了 pnpm-workspace.yaml 文件。如果没有这个文件,将会出现错误提示: –workspace-root may only be used inside a workspace 。
# Global install
npm install turbo --global
# Install in repository
pnpm add turbo --save-dev --workspace-root
2、在你的仓库根目录下,创建一个 turbo.json (或者turbo.jsonc)文件。
{
"$schema": "https://turbo.build/schema.json",
"tasks": {
"build": {
"outputs": ["dist/**"]
}
}
}
tasks下面的key,就是每个子包中的package.json中的scripts指令,如果每个子包都有build,则会并行运行。
更多turbo.json的配置,参考:https://turbo.build/repo/docs/reference/configuration
3、在你的 .gitignore 文件中添加 .turbo 。 turbo CLI 使用这些文件夹来保存日志、输出和其他功能。
4、添加一个 packageManager 字段到根 package.json
Turborepo 使用包管理器的信息来优化你的仓库。要声明你使用的包管理器,在根目录的 package.json 中添加一个 packageManager 字段(如果你还没有这个字段的话)。
{
"packageManager": "npm@8.5.0"
}
5、你现在可以使用 Turborepo 运行之前添加的任务了。
比如:turbo build check-types,会同时运行 build 和 check-types 任务。会使用 Workspace 的依赖图来按正确顺序运行任务。
验证缓存功能:
再次运行 turbo check-types build(更换顺序,不影响依赖顺序) ,你应该看到类似如下的终端输出,说明已经进行了缓存。
Tasks: 2 successful, 2 total
Cached: 2 cached, 2 total
Time: 185ms >>> FULL TURBO