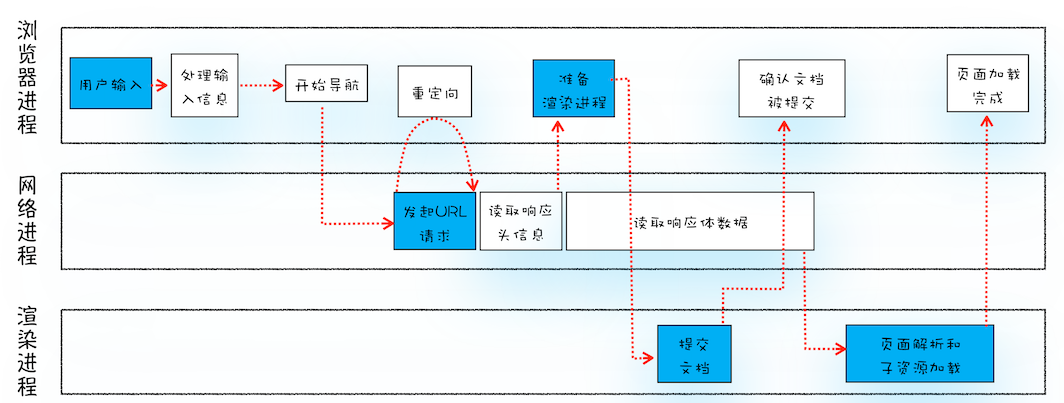
1、用户输入关键词,地址栏判断是搜索内容还是url地址。
- 如果是搜索内容,会使用浏览器默认搜索引擎加上搜索内容合成url;
- 如果是域名会加上协议(如https)合成完整的url。
2、然后按下回车。浏览器进程通过IPC(进程间通信)把url传给网络进程(网络进程接收到url才发起真正的网络请求)。
3、网络进程接收到url后,先查找有没有缓存。
- 有缓存,直接返回缓存的资源。
- 没有缓存。(进入真正的网络请求)。首先获取域名的IP,系统会首先自动从hosts文件中寻找域名对应的 IP 地址,一旦找到,和服务器建立TCP连接;如果没有找到,则系统会将网址提交 DNS 域名解析服务器进行 IP 地址的解析。
4、利用IP地址和服务器建立TCP连接(3次握手)。
5、建立连接后,浏览器构建数据包(包含请求行,请求头,请求正文,并把该域名相关Cookie等数据附加到请求头),然后向服务器发送请求消息。
6、服务器接收到消息后根据请求信息构建响应数据(包括响应行,响应头,响应正文),然后发送回网络进程。
7、网络进程接收到响应数据后进行解析。
- 如果发现响应行的返回的状态码为301,302,说明服务器要我们去找别人要数据,找谁呢?找响应头中的Location字段要,Location的内容是需要重定向的地址url。获取到这个url一切重新来过。
- 如果返回的状态码为200,说明服务器返回了数据。
8、好了,获取到数据以什么方式打开呢?打开的方式不对的话也不行。打开的方式就是 Content-Type。这个属性告诉浏览器服务器返回的数据是什么类型的。如果返回的是网页类型则为 text/html,如果是下载文件类型则为 application/octet-stream 等等。打开的方式不对,则得到的结果也不对。
- 如果是下载类型,则该请求会被提交给浏览器的下载管理器,同时该请求的流程到此结束。
- 如果是网页类型,那么浏览器就要准备渲染页面了。
9、渲染页面开始。浏览器进程发出“提交文档”(文档是响应体数据)消息给渲染进程,渲染进程接收到消息后会和网络进程建立传输数据的通道,网络进程将“文档”传输给渲染进程。
10、一旦开始传输,渲染进程便开始渲染界面。
(
传输的文件包含了html,css和javascript文件。
由于渲染机制过于复杂,所以渲染模块在执行过程中会被划分为很多子阶段,输入的 HTML 经过这些子阶段,最后输出像素。我们把这样的一个处理流程叫做渲染流水线。
子阶段包括如下几个阶段:构建 DOM 树、样式计算、布局阶段、分层、绘制、分块、光栅化和合成。
构建 DOM 树:
为什么构建DOM树?这是因为浏览器无法直接理解和使用 HTML,所以需要将 HTML 转换为浏览器能够理解的结构——DOM 树。
通过在开发者工具中可以输入 document 查看DOM树。可以看到,DOM 和 HTML 内容几乎是一样的,但是和 HTML 不同的是,DOM 是保存在内存中树状结构,可以通过 JavaScript 来查询或修改其内容。
样式计算:
样式计算的目的是为了计算出 DOM 节点中每个元素的具体样式,这个阶段大体可分为三步来完成。
- 把css转换成浏览器能识别的结构
转换后的结构可以输入 document.styleSheets 看到。
- 转换样式表中的属性值,使其标准化
比如将em,red,bold等转换成12px,rgb(255,0,0),font-weight:700等具体的值。
- 计算出DOM树每个节点的具体样式
用到css的继承性和层叠性。
布局阶段:
布局阶段就是需要计算出 DOM 树中可见元素的几何位置。分两个任务:
- 创建布局树
布局树就是创建一个只包含可见节点的树,像head标签,display:none等的元素都不加入布局树中。
- 布局计算
计算布局树节点的坐标位置了。布局的计算过程非常复杂,这里先跳过。
分层:
此时布局树有了,每个节点的样式有了是不是就可以开始渲染呢?
答案的是否定的。
此时渲染引擎还要为特定的节点生成专用的图层,并形成一颗图层树。
于是浏览器的页面实际上被分成很多图层叠加后形成了最终的页面。
但是并不是所有额节点都会生成图层。需要满足下面两点的任意一点才可以:
- 拥有层叠上下文属性的元素会被提升为单独的一层。(如:position,z-index,filter,opacity,transform等属性的元素)
- 需要被裁减的地方会被创建为图层。(比如元素超出裁减overflow:hidden)
图层绘制:
图层绘制把每个图层拆分成很多个小的绘制指令,然后再把这些指令按照顺序组成一个待绘制的列表。
而绘制一个元素通常需要好几条绘制指令,因为每个元素的背景,前景,边框等都需要单独的指令去绘制。
所以,该阶段的任务就是输出待绘制列表。
分块:
绘制列表有了,具体的绘制操作由合成线程来完成。当图层的绘制列表准备好之后,主线程会把该绘制列表提交(commit)给合成线程。
但是一般一个页面会很大,可能远大于视口的大小,基于这个原因,合成线程会将图层分为图块。这些图块的大小通常是 256x256 或者 512x512。然后合成线程会按照视口附近的图块来优先生成位图。
光栅化:
然而实际生成位图的操作是由栅格化来执行的。所谓栅格化,是指将图块转换为位图。
通常,栅格化过程都会使用 GPU 来加速生成,使用 GPU 生成位图的过程叫快速栅格化,或者 GPU 栅格化,生成的位图被保存在 GPU 内存中。
合成:
一旦所有图块都被光栅化,合成线程就会生成一个绘制图块的命令“DrawQuad”,然后将该命令提交给浏览器进程。浏览器进程里面有一个叫 viz 的组件,用来接收合成线程发过来的 DrawQuad 命令,然后根据 DrawQuad 命令,将其页面内容绘制到内存中,最后再将内存显示在屏幕上。
至此,一张漂亮的页面就渲染完成了*(渲染的完整示意图和简化流程在 06 )*。
)
11、传输完毕,渲染进程会发出“确认提交”消息给浏览器进程。
12、浏览器在接收到“确认提交”消息后,更新浏览器界面状态(包括地址栏信息,仟前进后退历史,web页面和网站安全状态)。
13、页面此时可能还没有渲染完毕,而一旦渲染完毕,渲染进程会发送一个消息给浏览器进程,浏览器接收到这个消息后会停止标签图标的加载动画。
自此,一个完整的页面形成了。